
Reinforcement learning — Step by Step Implementation using SARSA
In this tutorial, I have given the step by step implementation of Reinforcement Learning (RL) using SARSA algorithm. Before jumping on to coding and functions, I have briefly explained the subject to easily understand the code and the steps that have been followed one after the other. If this is your first time learning about RL-SARSA, I hope you will benefit from my tutorial below. I will also try to enhance this blog with the latest information as much as I can.
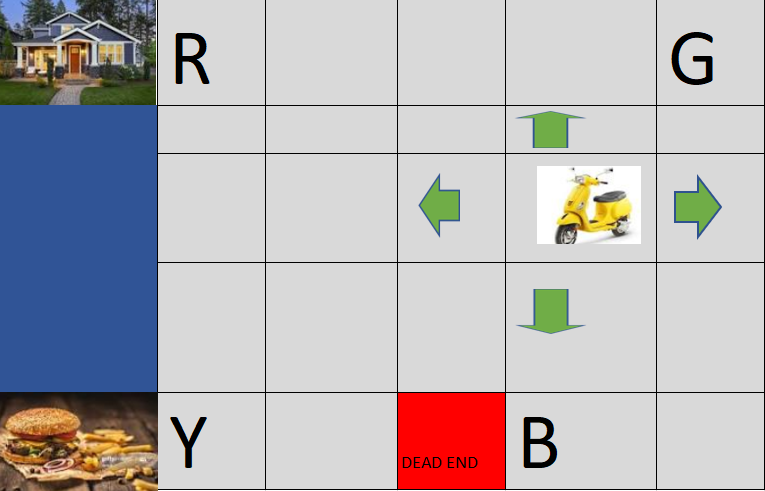
Take an example of a driverless scooter taxi (which performs the work of food delivery person) taking the food parcel from one place to another place.
Image:
Before proceeding further on implementing RL, we should know the following:
The main processes of RL are:
Observe, Decide, Act, receive, learn and Iterate
Observe means observing the environment of the agent
Decide means decide as per the observation
Acting means taking action on the decision
Receive means receive rewards or get penalized as per the action
Learn means to learn from previous actions and improve
Iterate means to repeat the entire process until success or the goal has been reached
The main components of RL are
Environment, Agent, Rewards, Goals and Actions, State, Policy
An agent isa learner and the decision-maker for eg: Taxi
The environment is the place where the agent learns and decides what actions to perform.
Action is a set of actions that the agent can perform.
State is the state of the agent in the environment.
A reward is nothing but a scalar value. For each action selected by the agent, the environment provides a reward. It can be a positive or negative reward. It can be instant or long-term reward
We need the above components to implement RL and to build Q table/Optimal policy
With respect above example with image, let’s arrive at these components and build Q table/Optimal Policy
States:
In the above image, think that it is an area divided to 5*5 grid which means it has 25 possible states. Current location of the scooter or bike taxi is (2,3).
This is just for an example. In a real-time scenario, the no of possible states might be in millions also 🙂
Here Food — states can be R, G, Y, B and inside scooter also and hence 5 states.
Locations where we can pick the food /delivering the food are 4
Hence Total number of possible states =
25 possible states * 5 Food states * 4 Locations for pick the food/deliver the food
= 500 possible states
Actions:
Actions could be the scooter moving up, down, right, left, picking the food, delivering the food. Hence totally 6 actions
Rewards:
When it comes to the rewards part, the scooter will receive a reward whenever it takes action.
It can be positive or negative. Rewards will be defined by the programmer and let’s define the
rewards for this example as below:
Reward to pick up the food from the right place: 10
Reward to deliver the food in the right place: 20
wrong moves = -1. This is called penalization when it does the wrong action. E.g.: Scooter has gone to the dead-end of the road, it will get a reward of -1.
Gym Package:
Gym is a toolkit which helps to develop and compare reinforcement learning algorithms. The gym library is a collection of test problems — environments — that anyone can use to test your reinforcement learning algorithms. These environments in the gym have a shared interface, which allows you to write general algorithms.
We have environments like FrozenLake-V0, Atari, 2D and 3D Robots, Taxi etc
The other env names can be found in the below link:
https://github.com/openai/gym/blob/master/gym/envs/
In OpenAI’s gym package: following functions can be used for implementing RL

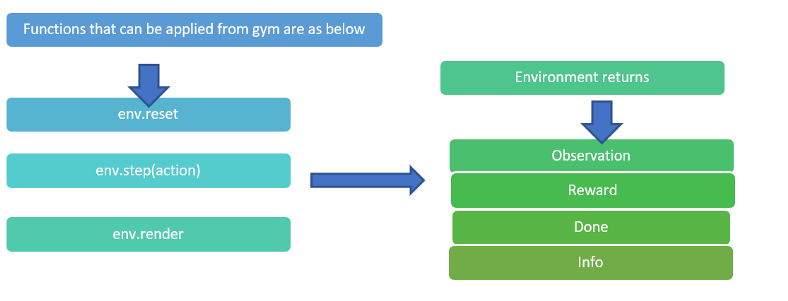
env.reset will return a random initial state and also resets the environment. We can also reset to a particular state.
env.step(action)will increase the time step in the environment.
env.render will be helpful in the visualization of the environment with agent location.
Observation indicates the observation of the environment
A reward is a reward achieved from the action done previously. It can be positive or negative
Done will tell if we have reached the goal or not. It will Be False if not reached else True.
Now let’s get in to step by step implementation:
Step1: #Import the following libraries


#Pickle file is mainly to store our Q table and optimal policy #information
Step2: #Build /Create the environment
(For now, we will use the existing environment in the gym )


To check for other environments in the gym, you can sue the following code


Step3: Initialize all the parameters along with the Q table as below:


#Q table initialization as below:


Initially, the values of the Q-table are initialized to 0. An action is chosen for a state. As we move, Q value is increased for the state-action whenever that action gives a good reward for the next state. If the action does not give a good reward for the next state, it is decreased.
Step 4:
PART-A:
Now proceed to define the Epsilon greedy method and SARSA algorithm to build Q table
We have to build a table called Q-table which will have dimensions SxA where S is the number of states and A is the number of actions.
For Every S (State) there are A’s (actions), the likeliness of selecting or choosing a particular action depends on the values in Q table. Those values in the Q table are also known as State-Action values.
SARSA depends on the current state, current action, reward obtained, next state and next action. SARSA stands for State Action Reward State Action which symbolizes the tuple (s, a, r, s’, a’). SARSA is an On Policy, a model-free method which uses the action performed by the current policy to learn the Q-value
#Write the below function to Choose the action based on Epsilon greedy method


In the above function if the random number generated is less than 0.1, we can go for Exploration else we can go for Exploitation (Q learning).
Exploration means we should try to get more details about the environment.
Exploitation means we have to aim for maximizing the reward by making use of the information which is already found.
#Use below SARSA formula to learn Q value and update Q table:

In the above formula, we have the current station and action, Next state and next action. We also have alpha which is the learning rate and gamma as the discount rate.
PART-B:
#Write a Function as below to create a Q table. This will include SARSA formula


Step 5: Do the training using epsilon greedy method and SARSA algorithm.
Here the hyperparameters are your total_no_episodes.

Step 6: #Evaluate your SARSA model by using the reward and total number of episodes information

Step 7: #Get the Q table and visualize the matrix

Sample Q with dimensions (SxA -> 500*6) can be as below:


### Note the above Q table is just a sample
Step 8: Randomly select the state and see how many steps it has taken to reach the goal using the Q table that is already created with the above steps


# sample visualizations of first 2 steps and last few outputs are as below (performed with env.render())


…… …. Other steps with visualization will be displayed …


In the above outputs, the highlighted marks determine the current position of the scooter taxi in the environment while the direction given in brackets gives the direction of movement that the agent (scooter) will make next.
Finally, the food is delivered/ dropped in the right place after 14 steps in the above case
Step 9: Load the Q table in a pickle file for later use and unload the same


Referred links:
Originally published on Medium






