Why Spark ruling Data Space !!

Why Spark ruling Data Space !!

One thought always comes to our mind that “What is Spark ? and why Industries are running behind it ?, also why Spark is ruling data space ?”. So hang tight and let me start with very funny example . Think of a beehive. You have a single queen and hundreds or thousands of worker bees. They have very distinct roles. The queen is largely responsible for the ‘brains’ of the entire operation, conducting the orchestra of worker bees who are fulfilling the hundreds of tasks that need to be accomplished. The worker bees are the executors, putting in the work required to accomplish those tasks.
What do Bees have to do with Apache Spark?
I feel my beehive example confused you more but be patient and let me help you to clear your confusion. They’ll come in handy soon. The formal definition of Apache Spark is that it is a general-purpose distributed data processing engine. It is also known as a cluster computing framework for large scale data processing.
Spark is built to handle extremely large scale data. The sheer amount of data being loaded into the spark application is enough to overwhelm almost any computer. To handle that, Spark utilizes multiple computers (called a cluster) to process the tasks required for that job and work together to produce the desired output.
This is where the bee analogy comes in. Let’s start with a diagram.
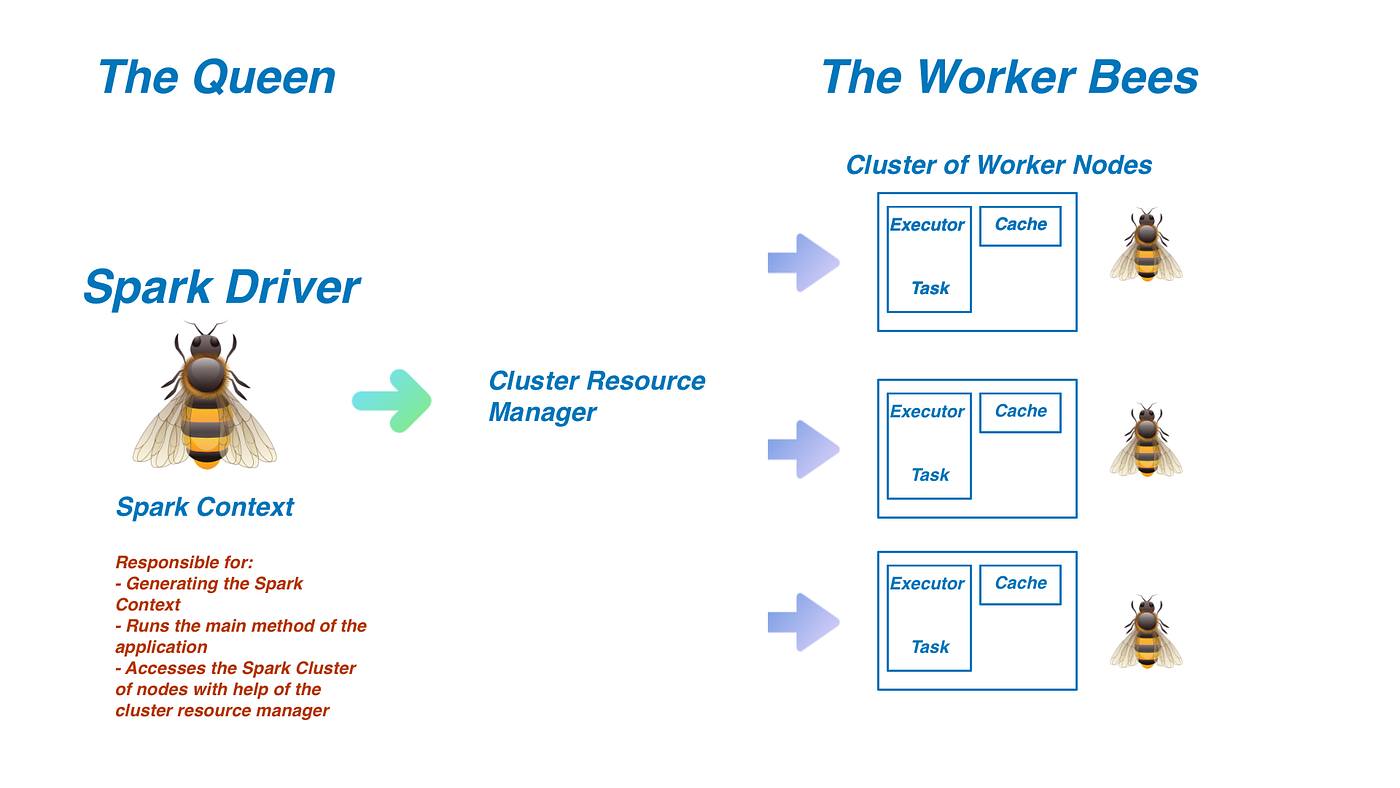
You will be laughing with this comparison. But let me explain you this diagram:
Spark has two main components, Spark driver and spark executors same as beeline queen and worker bees.
Spark Driver: The Queen Bee of the operation. The Spark Driver is responsible for generating the Spark Context. The Spark Context is extremely important since it is the entryway into all of Spark’s functionality. Using the Cluster Resource Manager (typically YARN, Mesos, or Standalone), the Driver will access and divide work between the cluster of Spark Executors (worker nodes). The Spark Driver is where the main method is run, meaning that any written program will first interact with the driver before being sent in the form of tasks to the worker nodes.
Spark Executors: The worker bees. The executors are responsible for completing the tasks assigned to them by the driver with the help of the Cluster Resource Manager. As they perform the tasks instructed to them, they will store the results in memory, referred to as a cache. If any one of these nodes crashes, the task assigned to that executor will be reassigned to another node to complete the task. Every node can have up to one executor per core. Results are then returned to the Spark Driver upon completion.
Apache Spark also takes advantage of in-memory caching for fast analytic queries for any data size. An in-memory cache is designed to store data in RAM and not on disk. You can use languages like: Scala, Python, R, and SQL to leverage Apache Spark.
Note: Spark is not a programming language. It is a general-purpose distributed data processing engine. Spark is written in Scala, a functional programming language. Spark, fortunately has a great Python integration called PySpark (which is what I use mostly) — it lets me interface with the framework in any which way I want.
How Apache Spark works ?
Now, you will be curious to know that how it works. So, let’s take a
further deep dive and understand spark architecture:

The first block you see is the driver program. Once you do a Spark submit, a driver program is launched and this requests for resources to the cluster manager and at the same time the main program of the user function of the user processing program is initiated by the driver program.
Based on that, the execution logic is processed and parallelly Spark context is also created. Using the Spark context, the different transformations and actions are processed. So, till the time the action is not encountered, all the transformations will go into the Spark context in the form of DAG that will create RDD lineage.
Once the action is called job is created. Job is the collection of different task stages. Once these tasks are created, they are launched by the cluster manager on the worker nodes and this is done with the help of a class called task scheduler.
The conversion of RDD lineage into tasks is done by the DAG scheduler. Here DAG is created based on the different transformations in the program and once the action is called these are split into different stages of tasks and submitted to the task scheduler as tasks become ready.
Then these are launched on the different executors in the worker node through the cluster manager. The entire resource allocation and the tracking of the jobs and tasks are performed by the cluster manager.
As soon as you do a Spark submit, your user program and other configuration mentioned are copied onto all the available nodes in the cluster. So that the program becomes the local read on all the worker nodes. Hence, the parallel executors running on the different worker nodes do not have to do any kind of network routing. This is how theentire execution of the Spark job happens.
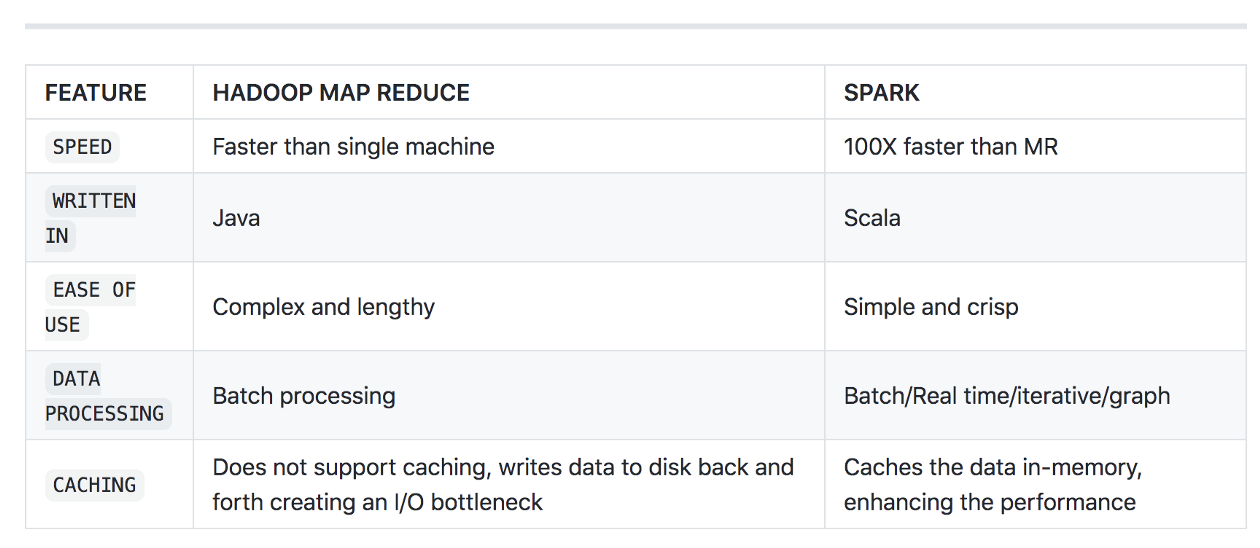
Differences b/w traditional Hadoop map-reduce and Spark: For those of you who have traditionally worked on map-reduce or Hadoop, you might wonder why Spark? Spark has a big margin of advantage starting from speed to easy of writing. Some of the stark differences are:
Why its ruling ?
There are many reasons for its ruling but I would like to list out few of them. First let me tell you that “What makes spark so special?” So, this is a simple three-fold answer. 1. SPEED, 2.EASE OF USE, 3. A UNIFIED ENGINE.
But let’s deep dive into few reach features.
- Fast processing:– The most important feature of Apache Spark that has made the big data world choose this technology over others is its speed. Big data is characterized by volume, variety, velocity, and veracity which needs to be processed at a higher speed. Spark contains Resilient Distributed Dataset (RDD) which saves time in reading and writing operations, allowing it to run almost ten to one hundred times faster than Hadoop.
- Flexibility:- Apache Spark supports multiple languages and allows the developers to write applications in Java, Scala, R, or Python.
- In-memory computing:- Spark stores the data in the RAM of servers which allows quick access and in turn accelerates the speed of analytics.
- Real-time processing:- Spark is able to process real-time streaming data. Unlike MapReduce which processes only stored data, Spark is able to process real-time data and is, therefore, able to produce instant outcomes.
- Better analytics:- In contrast to MapReduce that includes Map and Reduce functions, Spark includes much more than that. Apache Spark consists of a rich set of SQL queries, machine learning algorithms, complex analytics, etc. With all these functionalities, analytics can be performed in a better fashion with the help of Spark.
Scope: There are almost all the area and everyone can use spark in data space. Spark is a one-stop solution for many Big data-related problems. Some of the common use cases for Spark are:
1. Batch Processing (ETL)
2. Real time, well almost real time.
3. ML and Deep Learning
Data scientists use Apache Spark to perform advanced data analytics. Python brings an extensive set of advanced analytical functions that can be performed on data in Spark. Python is one of the more popular languages of the data science community and is also supported by Spark via a toolset called pySpark.
Data engineers are data designers or builders. They usually assist data scientists and application developers in the data curation journey. They develop the architecture for the organization based on use cases and needs.
Application developers can build solutions using Apache Spark. These applications are generally for analytical and business intelligence purposes. Spark is great for data analysis style applications and not for transaction processing applications.
BOTTOM LINE: Apache Spark was built in 2009 and made resilient by 2012 because MapReduce was slow and complicated, and people wanted something faster and easier. Apache Spark is fast and is far simpler to program than MapReduce. Imagine shoving a bunch of data into computer memory and being able to read it, process it, or do something rapidly. That is Apache Spark.In layman’s terms MapReduce was slow! SLOW + BIG DATA = NO JOY, thus we get Spark.
Apache Spark requires a decent amount of technical knowledge to make work. The average business person will require lots of help to get running on Apache Spark (being very generous). It is for programmers, data scientists, and highly technical unicorns.
CONCLUSION: Spark is an incredible technology and this article only touches the surface. I didn’t go into RDDs and other aspects but maybe in a future article I will. Hope to see you next time when I talk about installing and using Apache Spark in Kubernetes!
Thanks for reading, cheers!
Originally published on Medium
Clients:
Category:
Tech
Date:
20 August, 2021






